6 minutes
Approaches
Fuzzing can be segregated into different types based on the facet of the process we look at.
Program Structure
Knowledge of the internals of the target application directly results into maintaining a certain structure to the fuzzing process, which can result into achieving a higher code coverage in a shorter span of time. This results in a much more effective fuzzing exercise.
Blackbox Fuzzing
This approach involves the assumption that the target is a black box since we don’t have any knowledge of the internal behavior, source code or the implementation of the target application, hence the name.
Conceptually, blackbox fuzzing seems simple and straight up. We could simply loop an input generator and pass the generated test cases to the target application. However, the complexity of the fuzzing process increases with the complexity of the target application. Some examples are:
- Creating a harness for a GUI application to make sure input reaches the target as intended.
- Generating test cases that respect a certain input model, such as making sure that the mutated samples generated are all valid PDFs while fuzzing a PDF parser.
It all depends on the target being fuzzed.
Blackbox fuzzing is essentially employed when:
- Target is closed source, and no information is openly available about it.
- Cannot guide the fuzzing process, and it’s tough to capture any useful information from a fuzzing cycle since we don’t know about the target’s internals.
- Target is non-deterministic (gives different outputs for the same input everytime).
- Mutation of seed samples isn’t based on results of previous iteration.
- Target is slow.
- Overhead from instrumentation and statistical analysis might push the fuzzing exercise towards infeasibility and bad efficiency.
- Target is large.
- Processing all the data from a fuzzing cycle becomes overly complex.
The process can be easily scaled since not much processing is required to generate inputs and can be easily parallelized.
The downside of this technique is that it might only lead to the discovery of shallow bugs since the generated test cases do not evolve according to the output, and might fail to penetrate the target.
For example, fuzzing a release version of an application with a proprietary application would require blackbox approach, since in most cases no information is provided about it’s internals.
Whitebox Fuzzing
This approach involves knowledge of the target’s internals, the source code itself in most cases. This allows us to make use of techniques like:
- Source Code Instrumentation (putting code snippets at different locations in the source code to monitor the execution state).
- Symbolic Execution (analyzing constraints on inputs and conditional instructions).
- Taint Analysis (tracking the flow of a particular set of bytes).
All these techniques help us in following the flow of execution of the binary for a given test case, which gives us an insight over how the target is reacting towards the test case. From all this data, it becomes easier to generate test cases that allow us to reach certain critical program locations quicker.
However, all the aforementioned processes might add a significant overhead, which would in-turn slow the whole process down to an extent that blackbox fuzzing might become a more efficient solution.
For example, a developer might employ the whitebox approach to fuzz their application for bugs in the development cycle itself.
Greybox Fuzzing
The objective of this approach is to combine the efficiency of the blackbox approach while maintaining the effectiveness of the whitebox approach. It uses lightweight instrumentation techniques, which adds considerable performance overhead, but provides enough feedback about the program to successfully generate evolved, valid inputs on every iteration of the fuzzing cycle.
Input Generation
Test cases require to be constantly generated so that the fuzzing process doesn’t halt. This generation can be done in different ways.
Mutation based
An existing corpus of seed files is taken, and new test cases are generated by mutating (modifying) the files in this corpus. Simple scripts can get the job done.
The degree of mutation depends on the mutator. Some might introduce only a small change in the seed, like a couple of bytes or so, which creates a large corpus of similar test cases. Others might introduce changes so drastic that two generated test cases can’t be claimed to have come from the same seed. Which mutator to use is generally dictated by the target application.
The thing to note here is that this method does not respect the grammar of the file, that is, the random byte getting modified might belong to a format element, for example the ‘h’ in “”. This might cause an input to become invalid in cases where file format/grammar of the input is important.
Template based
The input is generated completely from scratch by a fuzzer that is aware of the input model, that is, adheres to a specified ruleset. It doesn’t depend on a pre-existing corpus of seeds. For such a task, complex methods like machine learning models might need to be employed to provide effective test cases. For example, a machine learning model can be trained to generate varying PDFs for a PDF parser we might want to fuzz. With enough data, the model could learn the grammatical syntax of the PDF file format and produce test cases which are valid PDF files.
Brute Force
Input generation is completely random.
Coverage Guided
The fuzzing environment is set up in a way that allows us to record the parts of the program that are being covered by the input and mark the ones that trigger new path (interesting inputs). When a new path is discovered, mutation can be performed on that particular input to ensure that the new test cases cover at least that much ground. The code coverage graph is thus an increasing graph.
For example, in the figure, once input[0] is found out to be ‘P’, mutation can be performed on the input that triggered this path to make sure this stage is always passed and that we are testing for the subsequent bytes.
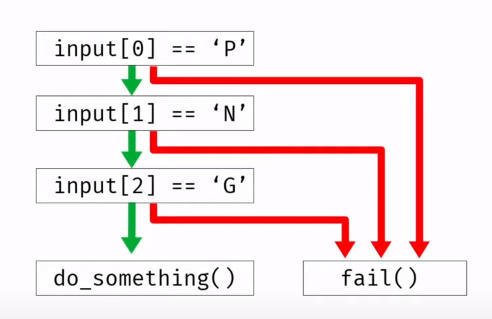 Coverage guided fuzzing.
Coverage guided fuzzing.
Input Structure
Fuzzers are used to generate all sorts of test cases. Some test cases might be valid, while others not. A valid test case is the one which is accepted by the target application. The chances of a generated seed being valid is inversely proportional to the complexity of the valid input format.
Smart Fuzzer
The class of fuzzers that recognizes the input model to make sure that most of the test cases generated are accepted. If the input model adheres to a certain file format, then the fuzzer would employ certain production rules to make sure that the test cases generated adhere to the required file format. If the input model can be represented as an AST (Abstract Syntax Tree), then the fuzzer would only employ transformations that randomly move complete set of nodes from one point to another.
Dumb Fuzzer
The class of fuzzers that do not require an input model and can be used to universally generate test cases for a wide variety of applications. However, their usability generally goes down with increasing input model complexity, since flipping random bytes would not care about maintaining a format in the generated test case.
fuzzingblackboxwhiteboxgreyboxdumb-fuzzersmart-fuzzercoverage-guidedmutator
1194 Words
2021-01-01 05:30 +0530